January 2, 2026
Day-2 Operations: Building Reliable, Scalable, and Operable Production Systems

By Shyam Kapdi
Improwised Technologies Pvt. Ltd.

By Satish Annavar
Improwised Technologies Pvt. Ltd.
Your production system launched successfully. Customers are onboarding. Revenue is flowing. Then, six months later, a routine upgrade triggers a cascade failure at 3 AM. Your engineering team spends the weekend putting out fires. Customer trust erodes. Cloud costs spike 40% with no corresponding increase in revenue. This isn’t bad luck it’s predictable neglect of Day-2 operations.
Most production failures don’t happen at launch. They emerge during post-go-live change: upgrades that drift configurations, scaling events that expose bottlenecks, dependencies that evolve incompatibly, and security patches that break assumptions. Organizations that treat Day-2 as “maintenance” accept fragility. Those who engineer it as a discipline achieve predictable upgrades, fast recovery, and sustainable unit economics.
This blog reframes Day-2 operations as a continuous value protection and optimization layer one that determines whether systems scale profitably or gradually erode trust and margin over time.
What Are Day 2 Operations
Day-2 Operations are the engineering, governance, and economic control layer that determines whether digital systems continue to deliver business value after launch under continuous change, scale, and risk.
Day-1: Focuses on initial provisioning, feature delivery, and time-to-market.
Day 2: Focuses on sustainability, error budget management, efficiency, and unit economics. It involves technical tasks such as patching distributed systems, rightsizing cloud resources, tuning auto-scaling policies, and conducting post-incident retrospectives.
At an executive level, Day-2 Operations answers a single strategic question:
Can we change safely, repeatedly, and profitably without eroding trust, margins, or delivery speed?
They include:
- Continuous upgrades (platform, application, security)
- Reliability engineering and operational excellence
- Cost, performance, and risk optimization
Day-1 vs Day-2 focus
- Day 1: Focuses on environment setup and deployment to achieve a go-live state.
- Day 2: Focuses on lifecycle management, error budget tracking, resource efficiency, and evolving the system under real-world load. This includes proactive security patching and automated vulnerability management to mitigate emerging threats, alongside continuous configuration drift detection to ensure the production environment remains aligned with the intended “source of truth” (Infrastructure as Code).
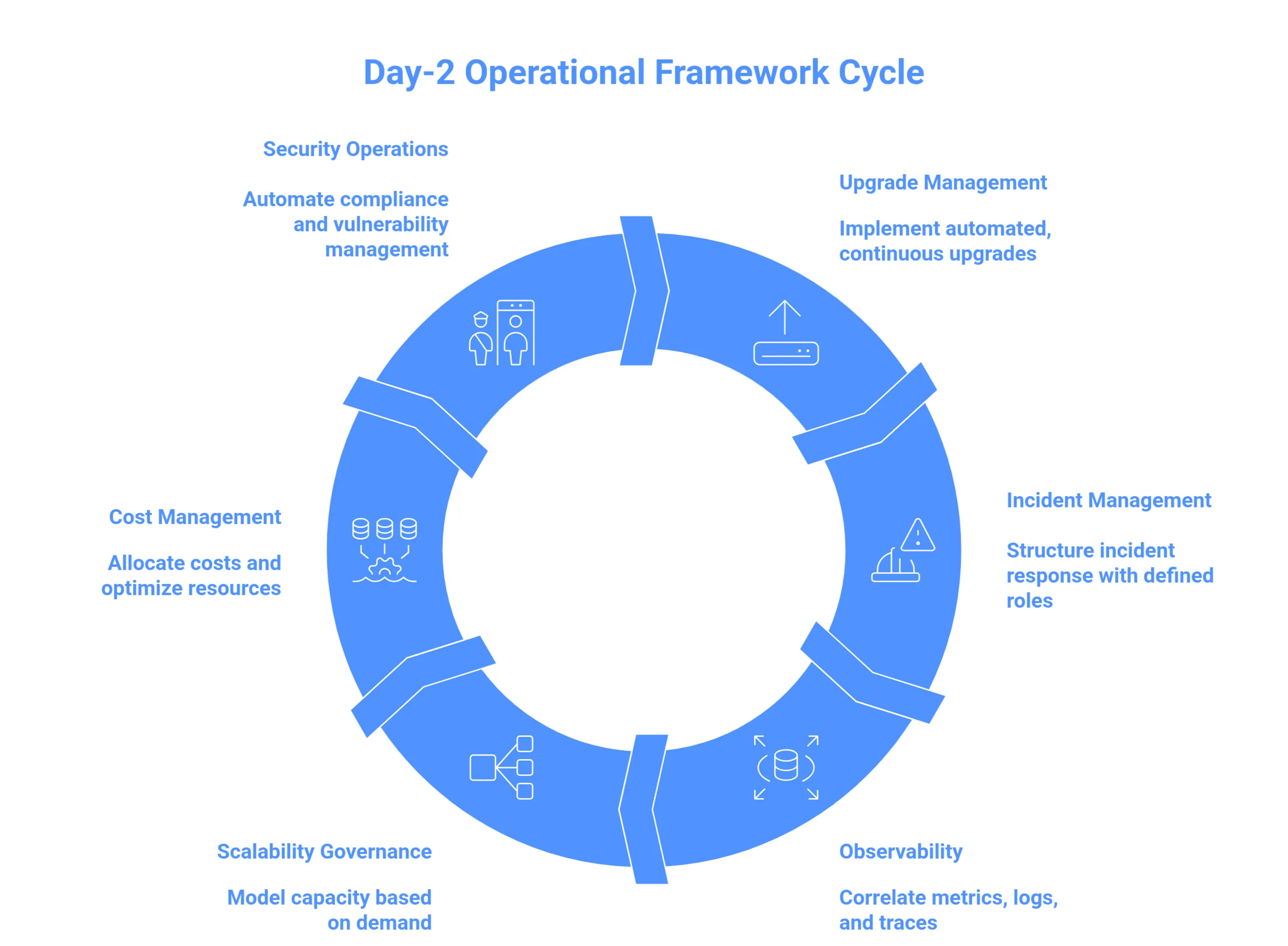
Key Processes for Effective Day 2 Operations
1. Upgrade & Change Management - The Controlled Business Event
Traditional IT treats upgrades as isolated maintenance events, typically manual and restricted to “quiet hours” to minimize perceived risk. This approach relies on manual rollback procedures and lacks blast radius controls, making the system fragile to configuration drift and human error during high-stakes maintenance windows.
Reframe upgrades as a continuous, automated business process. Transition to Risk-based Progressive Delivery using Canary or Blue-Green deployment strategies to limit the blast radius. Treat your infrastructure as code (IaC) to ensure versioned, repeatable environments. Integrate automated health checks and vulnerability scanning (e.g., Trivy) directly into the promotion pipeline to trigger automated rollbacks if Service Level Indicators (SLIs) deviate from the baseline.
This prevents “configuration drift” and ensures security debt isn’t inadvertently introduced during routine updates. It transforms upgrades from high-risk outages into auditable, reversible, and predictable business operations.
2. Incident Management - The Accountability Engine
Without a Day-2 operational framework, incident response is reactive and disorganized. Incidents escalate chaotically, multiple engineers make conflicting manual changes to production, root causes remain speculative, and the same systemic failures recur. This “firefighting” loop creates technical debt and erodes system availability.
Implement a structured Incident Command System (ICS) with pre-defined roles such as Incident Commander (IC), Communications Lead, and Operations Lead. Automate the response workflow by integrating observability alerts (e.g., Grafana) with collaboration platforms (e.g., Slack) to instantly provision dedicated “war rooms” and incident documents. Post-incident, conduct blameless post-mortems to identify “Contributing Factors” rather than “Human Error,” ensuring every outage is converted into a tracked, corrective action in the engineering backlog.
This structures chaos into a repeatable process, enforcing accountability and preventing the recurrence of known failure modes. It directly protects business revenue by reducing Mean Time to Resolution (MTTR) and building a culture of continuous improvement.
3. Observability vs. Monitoring - The Proactive Nervous System
Traditional Teams often drown in “symptom-based” alerts that signal high CPU but ignore user impact.
Move beyond basic monitoring to full Observability. Correlate the “Three Pillars” (Metrics, Logs, and Traces) to ask arbitrary questions about your system’s health. Implement SLO-driven alerting that triggers based on “Error Budget” consumption - noting when the user experience is actually degrading, rather than just when a server is busy.
This creates a tight feedback loop between production reality and engineering decisions, shifting effort from costly firefighting to proactive reliability engineering.
4. Scalability & Performance Governance - The Predictive Safety Margin
Systems over-provision to avoid performance issues, wasting budget. Or they under-provision, causing degradation during traffic spikes.
Model capacity based on business demand forecasts. Implement policy-driven auto-scaling (horizontal and vertical) and leverage serverless/elastic infrastructure models. Integrate performance regression testing into CI/CD.
This aligns infrastructure spend directly with business patterns, avoiding both over-provisioning (cost waste) and under-provisioning (reliability risk).
5: Cost & Unit Economics Management - The Margin Protection Layer
Without Day-2 financial governance, cloud bills often grow faster than revenue. Engineers lack real-time visibility into which microservices or architectural decisions drive spend, leading to “cloud shock.” In this reactive state, cost optimization becomes a disruptive quarterly fire drill rather than a continuous engineering discipline.
Adopt a FinOps model by implementing granular cost allocation tags by service, environment, and team to establish fiscal accountability. Deploy automated governance tools (e.g., Kubecost for container orchestration or Cloud Custodian for public cloud) to perform continuous resource rightsizing, identify “zombie” infrastructure, and manage Reserved Instance (RI) or Savings Plan coverage.
This prevents silent margin erosion at scale. By treating “Cost” as a first-class metric alongside performance and reliability, engineering leaders gain the telemetry needed to make informed architectural trade-offs that protect the company’s unit economics.
6. Security & Compliance Operations (DevSecOps in Day-2) - The Embedded Trust
Without Day-2 discipline, security is treated as a “point-in-time” audit exercise. This creates a security drift where vulnerabilities accumulate in dependencies, container images, and running kernels between audits. In this reactive model, static credentials remain unrotated, and a single perimeter breach allows unrestricted lateral movement across the internal network.
Shift security from a gatekeeper to an operational discipline. Implement Policy-as-Code to automate compliance guardrails at the CI/CD and admission controller levels. Move beyond static scanning to Continuous Vulnerability Management across the full stack (source code, container images, and active runtime). Centralize secrets management with dynamic, short-lived credentials and automated rotation (e.g., HashiCorp Vault). Enforce Micro-segmentation and Zero Trust architectures to ensure that identity and encryption are verified for every request, effectively restricting lateral movement if a service is compromised.
This reduces the attack surface and minimizes the “Mean Time to Remediate” (MTTR) for security vulnerabilities. Security becomes a continuous runtime protection layer that enables high velocity without compromising the organization’s risk posture.
Measuring Day 2 Success
Delivery & Change Effectiveness (DORA Metrics)
- Deployment Frequency: The frequency at which your organization successfully deploys code to production or releases it to end users. (Note: While velocity is the goal, DORA specifically measures the rate of successful pushes to define stability.
- Lead Time for Changes: The amount of time it takes for a code commit to be successfully running in production.
- Change Failure Rate: The percentage of changes to production or releases to users that result in degraded service (e.g., lead to service impairment or outage) and subsequently require remediation (e.g., a hotfix, rollback, patch).
- Failed Service Recovery Time: The time it takes to restore service when a service incident or a defect that impacts users occurs (e.g., unplanned outage).
Optimize for recoverability, not just delivery speed.
Reliability & User Impact
The Four Golden Signals: Monitor the essential metrics of a distributed system to maintain a high-level view of health:
- Latency: The time it takes to service a request (distinguishing between successful and failed requests).
- Traffic: The demand placed on the system (e.g., HTTP requests per second or concurrent sessions).
- Errors: The rate of requests that fail (explicitly, implicitly, or by policy).
- Saturation: A measure of your “fullness,” emphasizing the most constrained resource (e.g., memory, I/O, or thread pool exhaustion).
SLO/SLI Compliance: Sustained adherence to Service Level Objectives (SLOs), which are target values for specific Service Level Indicators (SLIs) (e.g., 99.9% of requests must succeed). This defines the “Error Budget” available for Day-2 changes.
Mean Time to Detect (MTTD): The average time it takes for your observability stack to identify a service-impacting incident. Effective Day-2 operations aim to minimize MTTD so that resolution begins before the Error Budget is exhausted or the SLO is violated.
Operational Efficiency
- Toil Management: Measuring the ratio of Toil (manual, repetitive, automatable operational work) versus Reliability Engineering (feature work and system improvement). In a mature Day-2 environment, toil should be capped (typically at 50%) to prevent burnout and ensure engineering velocity.
- Automation Efficacy: The percentage of manual interventions replaced by Self-healing mechanisms or Automated Runbooks. This tracks the reduction of human touchpoints during deployment pipelines and incident response.
- Defect Density in Automation: Monitoring the stability of automated scripts to ensure automation itself does not become a source of new production failures.
Persistent toil indicates architectural or operational debt.
Foundational Platform Health Signals
Track as leading indicators, interpreted only in correlation with reliability outcomes:
Network Health: * Latency: Round-trip time (RTT) at the VPC or service-mesh layer.
- Packet Loss/Retransmissions: Indicators of congestion or faulty network interfaces.
- Bandwidth Utilization: Current throughput vs. provisioned NIC or NAT Gateway limits.
Infrastructure Health:
- CPU Saturation: Tracking “CPU Load” or “Run Queue” length rather than just utilization percentage.
- Memory Pressure: Monitoring swap usage and OOM (Out of Memory) Killer events.
- Storage I/O: Monitoring Disk I/O latency (iowait) and IOPS throttling, especially on burstable cloud volumes (e.g., AWS GP3 credits).
- Resource Throttling: Tracking CPU CFS (Completely Fair Scheduler) periods for containerized workloads.
Secure Your Scale: Day-2 Action Plan
Day-2 operations mature differently across organizations - there’s no universal playbook. What works for a high-growth SaaS platform differs from what’s needed in regulated financial services or multi-regional e-commerce.
If you’re navigating the transition from reactive firefighting to proactive operational discipline, or evaluating where to invest next in your production infrastructure, we’ve helped engineering teams diagnose gaps, prioritize capabilities, and build sustainable operational foundations.
The best conversations start with your specific context: your scale, your constraints, your next inflection point. We’re here when you’re ready to explore what operational maturity looks like for your systems.
Frequently Asked Question
Get quick answers to common queries. Explore our FAQs for helpful insights and solutions.

By Shyam Kapdi
Improwised Technologies Pvt. Ltd.

By Shyam Kapdi
Improwised Technologies Pvt. Ltd.

December 17, 2025
Cloud to On-Premises Migration: Costs, Performance & Strategic Benefits
By Shyam Kapdi
Improwised Technologies Pvt. Ltd.
Optimize Your Cloud. Cut Costs. Accelerate Performance.
Struggling with slow deployments and rising cloud costs?
Our tailored platform engineering solutions enhance efficiency, boost speed, and reduce expenses.